
Researchers encoded six files into DNA: a full computer OS, a movie, a $50 Amazon gift card, a computer virus, a Pioneer plaque, and a 1948 study by information theorist Claude Shannon.
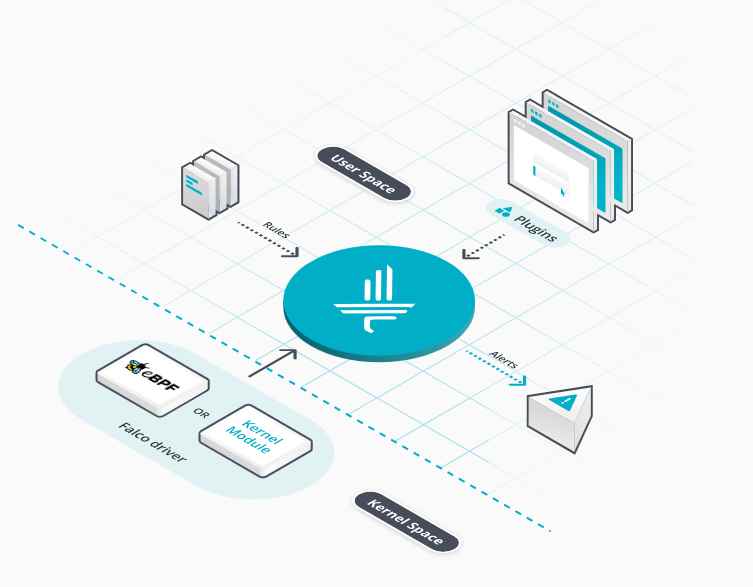
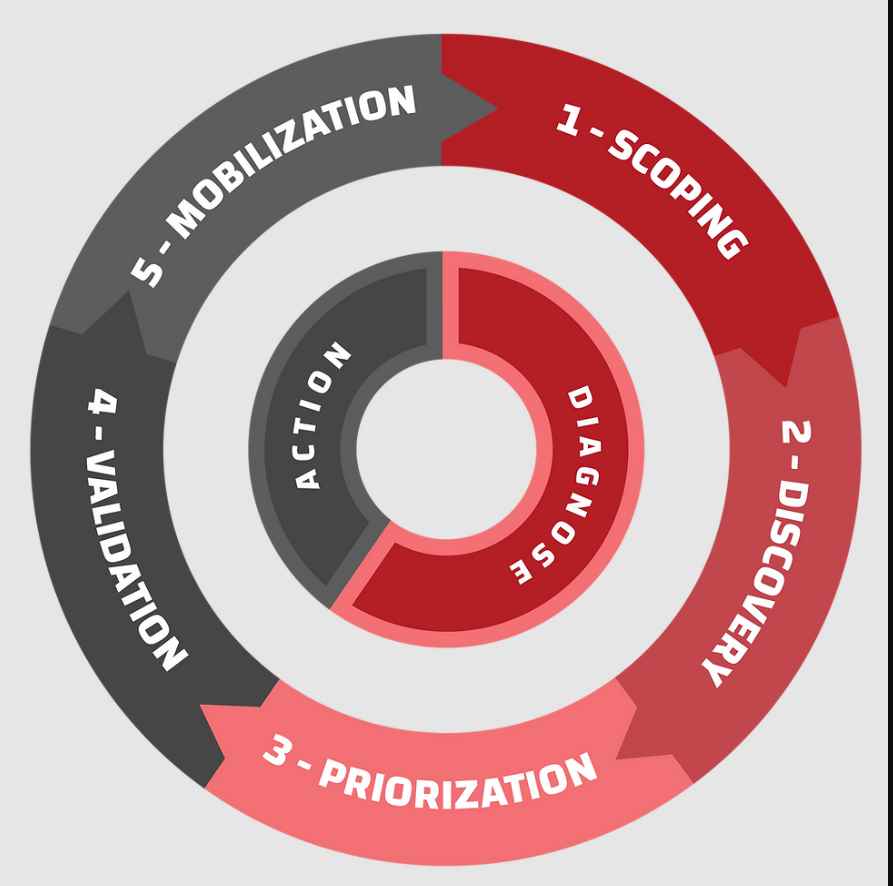
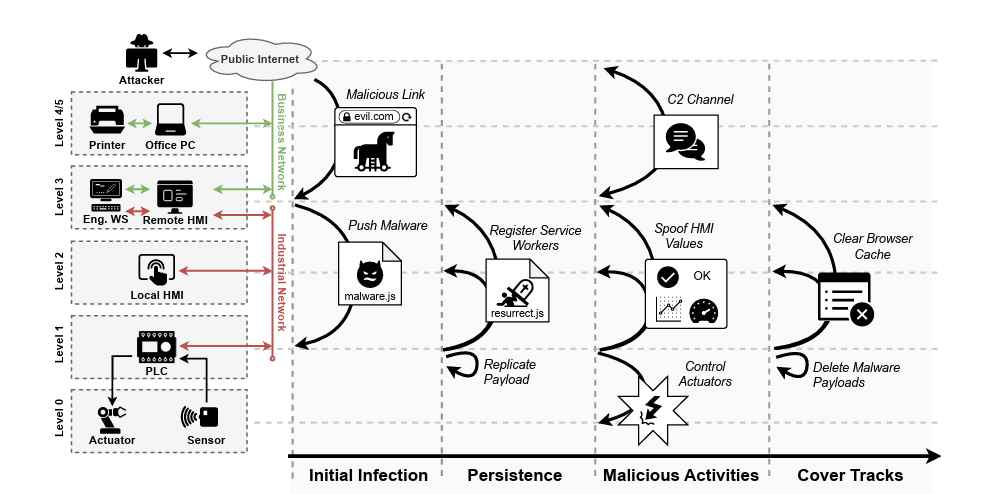
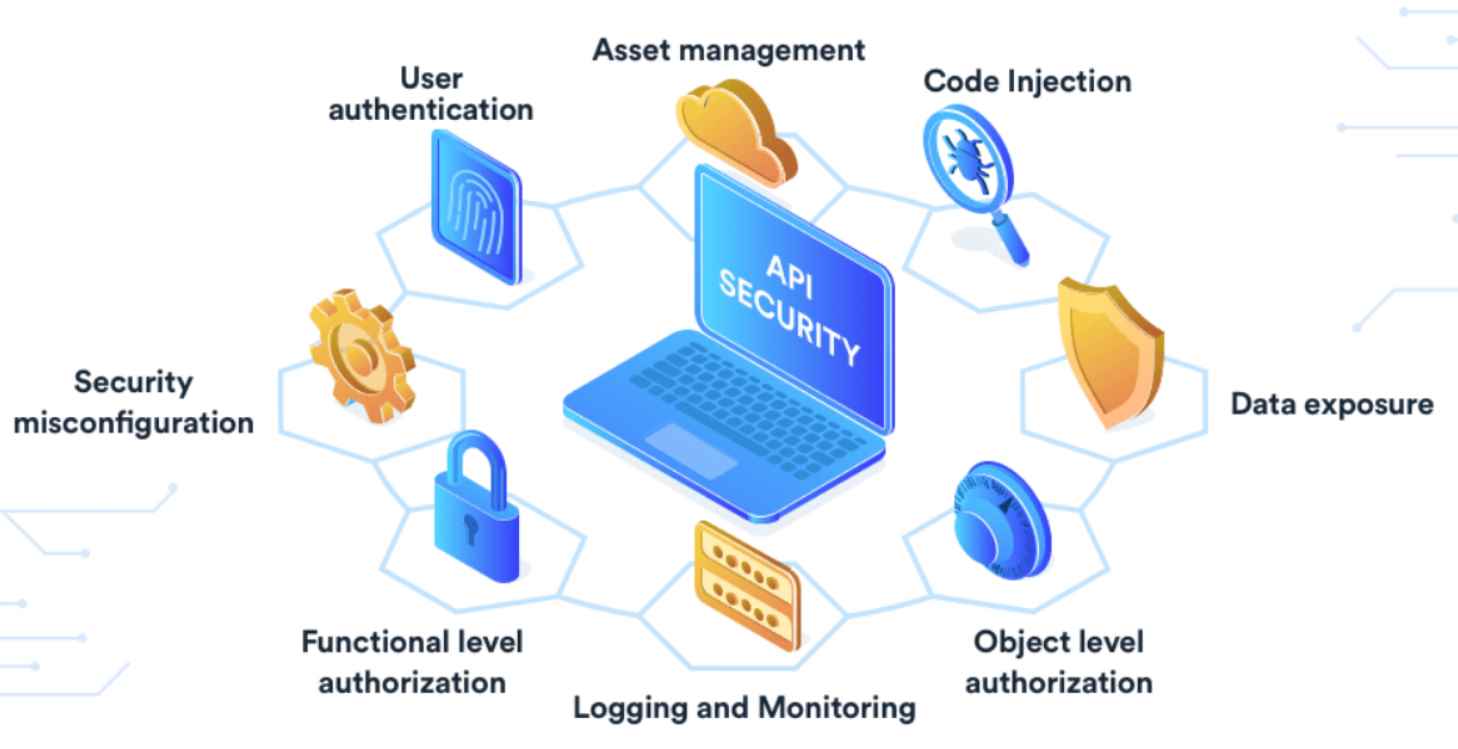





Working as a cyber security solutions architect, Alisa focuses on application and network security. Before joining us she held a cyber security researcher positions within a variety of cyber security start-ups. She also experience in different industry domains like finance, healthcare and consumer products.


