
I’ve previously written about fuzz testing, which feeds intelligently crafted input to a target program to exercise corner cases and find bugs, highlighting how Fastly uses American Fuzzy Lop to proactively find and mitigate bugs in some of the servers we rely on.
OSS-Fuzz is an effort led by Google to help make open source software (OSS) more secure and stable by fuzz testing OSS projects continuously. In a nutshell, Google security engineers are crowdsourcing development of fuzz testing integrations for ubiquitous open source projects and applying massive computing resources to find (and privately report) bugs in them. This distributed approach is similar to the one taken in the self-service secure development lifecycle (SDL) that the Slack security team has deployed to their growing development organization. (More about that later.)
OSS-Fuzz is an innovative project that is both advancing the state of the art in OSS security engineering and immediately improving the overall quality of the software that serves the internet. You can read more about it here and here. They even recently started offering patch rewards for project integrations. In an ongoing effort to provide a secure platform for our customers, we forked the open-source OSS-Fuzz project to bootstrap our own internal continuous fuzzing capability. Continuous fuzzing allows us to proactively find and mitigate bugs, keeping our customers secure while contributing to the overall security of the internet.
In this blog post, I’ll describe how to use the open source components of google/oss-fuzz to bootstrap self-service continuous fuzzing for both private and public software using h2o, Fastly’s HTTP/2 proxy, as a running example.
The benefits of fuzzing continuously
One of the difficult questions in fuzzing is deciding when to stop devoting resources to fuzzing a given target and move on.
OSS-Fuzz answers this question by supplying a framework for continuously fuzzing the latest version of a target program until the next version of the program is available. This is a pragmatic solution that considers the fact that new, previously-unfuzzed code is more likely to contain discoverable issues as well as providing assurance against regressions that might crop up in the codebase.
Once integration work for a project is done, OSS-Fuzz feeds the fuzz targets to ClusterFuzz, which will run iterations of the target under fuzz testing frameworks like LibFuzzer and AFL.
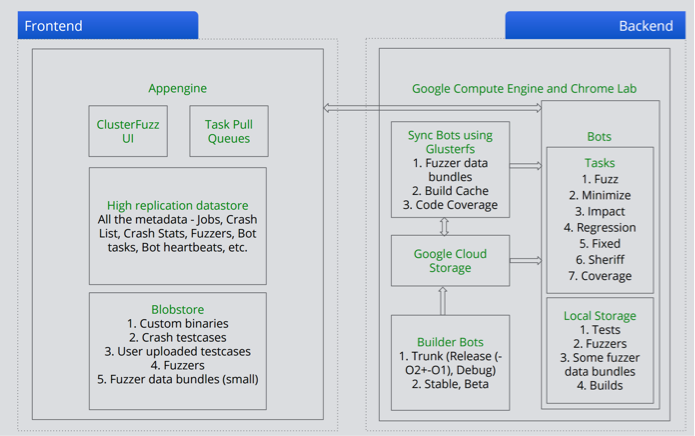
ClusterFuzz architecture diagram circa 2015. Src: Abhishek Arya / nullcon
One of the clever aspects of OSS-Fuzz is that anyone can apply to write an integration for an open source project. By maintaining a usable project integration framework, project developers can do parts that are simple for them but usually time-consuming for security engineers (like learning the project’s build system to write a simple fuzzer integration), and the security engineers can focus on the framework and generalized fuzzing innovations that benefit all the target projects.
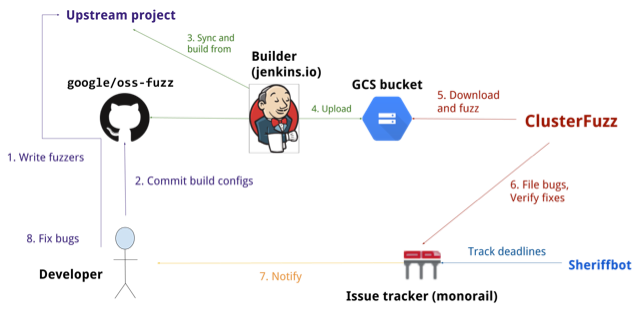
OSS-Fuzz workflow. Src: google/oss-fuzz.
We’ve added fuzz targets for the public version of h2o, Fastly’s HTTP/2 proxy, to Google OSS-Fuzz. You can check out the OSS-Fuzz integration code here; the fuzz target source can be found here. Along the way we used a combination of harvesting inputs from the h2o unit tests, manually crafting files, and distilling the results of some fuzz runs to produce seed corpora for our fuzz targets.
Overall working with Google OSS-Fuzz has been a great experience for the h2o team — we’ve uncovered bugs in h2o, gained assurance around the codebase, and the HTTP/2 seed corpus we published for this effort was used to uncover bugs in nghttp2.
What about private code?
While historically Fastly has been using fuzz testing to help secure critical code periodically, the Fastly security team is rolling out a self-service continuous fuzzing capability to both expand coverage of fuzzers and ensure they are run systematically as part of Fastly’s development and deployment processes.
Because some of our code is not open source, we needed to develop a capability to continuously fuzz private projects to support this effort. We’ve arrived at two high-level uses for this capability so far:
- To help secure closed-source software and private forks
- To seamlessly smoke-test changes to software that are headed for Google OSS-Fuzz
The first use case has been a longstanding goal, but the second one didn’t dawn on us until Google OSS-Fuzz was announced.
Like many OSS-friendly companies, the Fastly team regularly makes improvements to forks of open source software and contributes the production-tested changes upstream. In the case of h2o, we often make changes to the proxy in-house and carefully test and deploy them before we contribute the patches back to the public repo. Continuously fuzzing our internal fork of h2o catches bugs closer to when they are committed, but it also gives us a place to experiment with changes to the public h2o OSS-fuzz public integration.
Minimum Viable Fuzzer
The self-service secure development lifecycle (SDL) is a powerful concept for scaling security in fast-growing development teams, an idea we learned about from Leigh and Ari of the Slack security team. One technique they use for their self-service SDL is building automated services that engineers can use to develop secure systems, making efficient use of finite engineering and security team resources.
We’ve had success using this model in other parts of the SDL at Fastly, so we decided to take the same self-service approach for fuzzing. However, bootstrapping a self-service continuous fuzzing system is a significant undertaking, as it involves:
- Developing a project integration framework
- Providing guidance for development teams on how (and why) to integrate fuzzing
- Building and managing fuzzing infrastructure
- Assuring the security team that the system is providing value
While locking the doors, closing the blinds, and building a private continuous fuzzing cluster was a tempting place to start, we realized that approach introduced a lot of risk: Will engineers really use the system? How much work will this be? Is building out fuzzing a good use of limited AppSec resources? Will the fuzzers uncover bugs that matter? Will the service ultimately provide systemic security assurance?
In order to help ensure this project was a success, we decided to take a page from the startup playbook and take a “minimum viable product” (MVP) approach to developing our private continuous fuzzing capability. The idea was to focus on tasks that would address the riskiest parts of the project at the expense of well-understood automation that could be implemented later:
1. Draft how developers will interact with the service
2. Integrate with key projects
3. Catch some important bugs (i.e., prove it works)
4. Start integrating feedback
MVP plan
OSS-Fuzz FTW
The OSS-Fuzz project has done an excellent job designing a usable, well-documented fuzz integration framework. At this point you can probably see where this is going: we decided to modify Google OSS-Fuzz to build an MVP continuous fuzzing system for private projects at Fastly.
Google OSS-Fuzz already supplies a proven process for project integration, so we achieve goals #1 and #2 in the list above essentially “for free” — with some simple tailored guidance and training, developers can lean on the open source documentation and examples for project integration.
Production-tested, documented project integration framework available in google/oss-fuzz
There was still some work to do to get to an MVP: google/oss-fuzz does not include ClusterFuzz, the part of Google’s fuzzing system that actually manages production fuzz jobs.
[x] Draft how developers will interact with the service
[x] Integrate with key projects
[ ] Catch some important bugs (i.e., prove it works)
[ ] Start integrating feedback
Tasks #1 and #2 addressed
Just enough ClusterFuzz
google/oss-fuzz includes tooling to “smoke test” fuzzing integrations locally. For example, you can build and test the public h2o URL fuzzer like this:
$ git clone https://github.com/google/oss-fuzz
$ cd oss-fuzz
$ python infra/helper.py build_fuzzers h2o
$ python infra/helper.py run_fuzzer h2o ./h2o-fuzzer-url
After requisite cloning, these commands will spin up docker containers to:
- Build the h2o fuzz targets from scratch
- Run the h2o URL fuzzer fuzz target
This is designed to allow an OSS-Fuzz project integrator to make sure the fuzz targets compile, link, and won’t crash immediately when they get to ClusterFuzz. While not an ideal solution for long-term jobs,these testing tools can be repurposed: they supply a primitive capability to run ClusterFuzz-compatible fuzz targets that the google/oss-fuzz tooling produces.
MVP fuzz runner
So we decided that, with a little glue, this tooling might work well enough to run fuzz jobs in containers as part of a continuous fuzzing MVP. To test this idea, we claimed a spare (beefy) Fastly edge cache server from our lab, hacked the OSS-Fuzz tooling a little (more on this below), and invoked a set of run_fuzzer containers, using the supported LibFuzzer -worker and -jobs options to balance cores between all fuzz targets.
for project, targets in projects.items():
# Build fuzzers
if args.build:
build(project)
# Run fuzzers
for target in targets:
p = run_fuzzer(project, target,
["-workers=%d" % n_workers,
"-jobs=%d" % n_workers,
"-artifact_prefix=%s" % target.strip("./")])
Simplified code for fuzz runner
Accessing private code repositories
By default, OSS-Fuzz clones projects from public source code version control servers, like github.com, and then builds fuzz targets from them. In order to support private repositories for an MVP, we decided to forward the invoking shell’s ssh-agent (SSH_AUTH_SOCK) to the fuzz target building container and pull in private code via the OSS-Fuzz project’s build.sh, rather than its Dockerfile.
def build_fuzzers(build_args):
"""Build fuzzers."""
parser = argparse.ArgumentParser('helper.py build_fuzzers')
[...]
parser.add_argument('-A', dest='forward_ssh', default=False,
action='store_const', const=True, help='Forward SSH to container.')
[...]
if args.forward_ssh:
ssh_auth_sock = os.environ['SSH_AUTH_SOCK']
command += ['-v', '%s:/ssh-agent' % ssh_auth_sock, '-e',
'SSH_AUTH_SOCK=/ssh-agent']
[...]
command += [
'-v', '%s:/out' % os.path.join(BUILD_DIR, 'out', project_name),
'-v', '%s:/work' % os.path.join(BUILD_DIR, 'work', project_name),
'-t', 'gcr.io/oss-fuzz-base/%s' % project_name
]
Snippet adding ssh-agent forwarding to infra/helper.py’s build_fuzzers
While not an ideal long-term solution, this solved two problems quickly:
- The security team could automate rebuilding private fuzz targets without provisioning (or managing) additional repo access secrets.
- Developers could build and test integrations in their personal development environments without having to make any administrative changes to their project.
We anticipated making architectural changes to the fuzz target build process to better align with Fastly’s existing project deployment workflows, as well as for efficiency, which also made us feel slightly better about taking this shortcut initially.
Preserve the corpus
One of the strengths of continuous fuzzing is that, over time, you build a seed corpus (or queue) that can be used to help guide subsequent fuzzing campaigns. By default, google/oss-fuzz fuzz-runner container invocations don’t remember the progress they’ve made in fuzzing — that is left to ClusterFuzz. To remedy this for an MVP, we simply modified google/oss-fuzz to preserve its seed corpus directory between invocations of the container. We would then periodically, manually share and distill the seed corpora between similar fuzz targets to improve efficiency.
OSS-Fuzz provides a LibFuzzer-compatible interface to the fuzz frameworks it uses, which means files that increase coverage in the target (i.e., the fuzzer target) are stored in the directory passed to the fuzzer via its CORPUS_DIR argument. The changes needed here will depend on your environment, but in our case we simply modified the run_fuzzer command to use the seed_corpus directory for the target project instead of a ephemeral directory in /tmp.
SEED_CORPUS="${FUZZER}_seed_corpus.zip"
if [ -f $SEED_CORPUS ]; then
echo "Using seed corpus: $SEED_CORPUS"
- rm -rf /tmp/seed_corpus/ && mkdir /tmp/seed_corpus/
- unzip -d /tmp/seed_corpus/ $SEED_CORPUS > /dev/null
- CMD_LINE="$CMD_LINE /tmp/seed_corpus/"
+ CORPUS_DIR=$OUT/seed_corpus
+ mkdir -p $CORPUS_DIR
+ unzip -od $CORPUS_DIR $SEED_CORPUS > /dev/null
+ CMD_LINE="$CMD_LINE $CORPUS_DIR"
fi
echo $CMD_LINE
Changes to a legacy infra/base-images/base-runner/run_fuzzer to preserve seed corpora
Resource management
While excellent for project fuzzer integrations, using containers for isolating long-running fuzz jobs can be dicey: fuzzing can consume excess resources and otherwise make the underlying operating system unstable, which can lead to incidental interactions between fuzz jobs, false positives, and so on. Google ClusterFuzz, for example, builds fuzz targets binaries in containers but ultimately schedules and runs fuzz jobs in virtual machines, which provide more robust isolation.
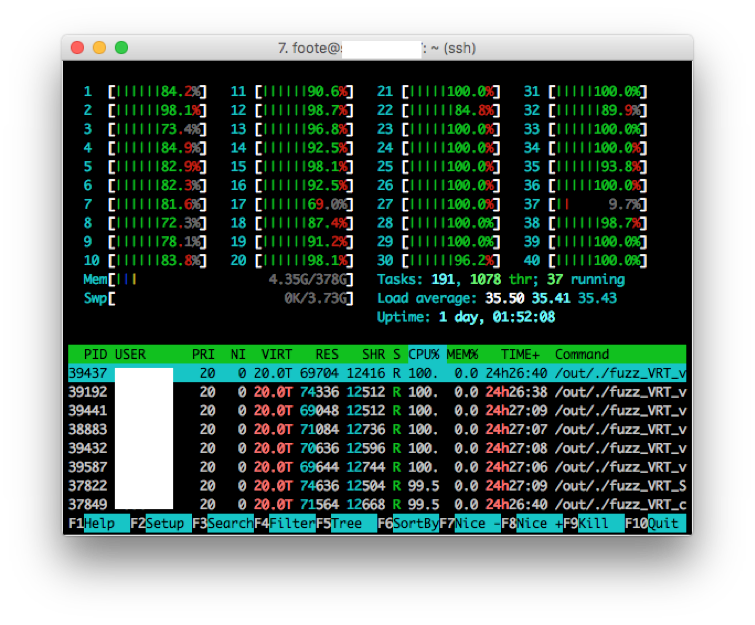
Basic MVP monitoring via perl scripts and system tools like htop
For our MVP, we decided to simply cut this corner: in our ongoing effort to take smart shortcuts in the interest of getting feedback early (and decreasing overall project risk), we were monitoring system resource usage and crashes regularly, so it would be easy to spot any bugs that arose from using containers. We also figured we would tailor the fuzzer execution engine for efficiencies and any peculiarities of our environment later, and that these sorts of changes would be relatively easy (they wouldn’t involve changing project integrations or re-training developers, for instance).
MVP deployed
With the ability to build fuzz targets from private repositories and run them on our infrastructure, we were able to achieve goals #3 and #4 for the MVP project.
[x] Draft how developers will interact with the service
[x] Integrate with key projects
[x] Catch some important bugs (i.e. prove it works)
[x] Start integrating feedback
Ship it!
While the list above highlights the major changes we made to make OSS-Fuzz work for private repositories, I’ve omitted a lot of smaller and environment-specific changes we made (and backlogged) along the way. If you’d like to learn more about the features that can be built into a continuous fuzzing system, I recommend checking out Abhishek Arya’s ClusterFuzz presentation (2015).
Source:https://www.fastly.com/blog/how-bootstrap-self-service-continuous-fuzzing








Working as a cyber security solutions architect, Alisa focuses on application and network security. Before joining us she held a cyber security researcher positions within a variety of cyber security start-ups. She also experience in different industry domains like finance, healthcare and consumer products.


